在人工智能基礎(chǔ)學(xué)習(xí)中,掌握數(shù)據(jù)處理、分類算法和可視化技術(shù)是至關(guān)重要的。本文將介紹如何使用Jupyter Notebook完成Iris數(shù)據(jù)集的Fisher線性分類任務(wù),并深入探討數(shù)據(jù)可視化技術(shù)的應(yīng)用。Iris數(shù)據(jù)集是一個經(jīng)典的多變量數(shù)據(jù)集,包含三種鳶尾花的特征數(shù)據(jù),非常適合用于分類算法的入門實踐。
我們需要導(dǎo)入必要的Python庫,包括pandas用于數(shù)據(jù)處理,numpy用于數(shù)值計算,matplotlib和seaborn用于數(shù)據(jù)可視化,以及scikit-learn中的Fisher線性判別分析(LDA)模塊。在Jupyter中,可以通過代碼單元格依次安裝和導(dǎo)入這些庫。
加載Iris數(shù)據(jù)集。scikit-learn庫內(nèi)置了該數(shù)據(jù)集,我們可以直接使用load_iris()函數(shù)獲取數(shù)據(jù)。數(shù)據(jù)集包括特征(如花萼長度、寬度,花瓣長度、寬度)和標(biāo)簽(鳶尾花種類)。通過pandas的DataFrame結(jié)構(gòu),可以方便地查看數(shù)據(jù)的基本信息,如描述性統(tǒng)計和缺失值情況。
數(shù)據(jù)預(yù)處理是機器學(xué)習(xí)的關(guān)鍵步驟。我們需要檢查數(shù)據(jù)是否需要標(biāo)準(zhǔn)化或歸一化,但I(xiàn)ris數(shù)據(jù)集通常已經(jīng)經(jīng)過處理,可以直接使用。然后,將數(shù)據(jù)集劃分為訓(xùn)練集和測試集,以確保模型的泛化能力。scikit-learn的train<em>test</em>split函數(shù)可以輕松實現(xiàn)這一點。
Fisher線性分類(通過LDA實現(xiàn))是一種監(jiān)督學(xué)習(xí)算法,旨在找到最佳投影方向,使得類間距離最大化、類內(nèi)距離最小化。在scikit-learn中,使用LinearDiscriminantAnalysis類可以快速構(gòu)建模型。初始化LDA模型,然后使用訓(xùn)練數(shù)據(jù)擬合模型,最后對測試數(shù)據(jù)進(jìn)行預(yù)測。通過準(zhǔn)確率、混淆矩陣等指標(biāo)評估模型性能,可以發(fā)現(xiàn)Fisher分類在Iris數(shù)據(jù)集上通常能達(dá)到很高的準(zhǔn)確率。
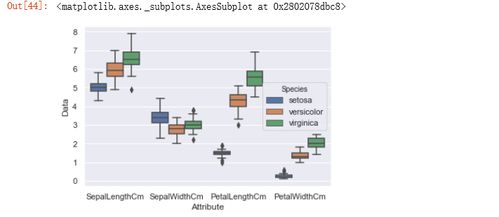
數(shù)據(jù)可視化技術(shù)在此過程中扮演著重要角色。我們可以使用matplotlib和seaborn繪制各種圖表來理解數(shù)據(jù)和模型結(jié)果。例如:
- 散點圖:展示特征之間的關(guān)系,如花萼長度與寬度的分布,并用顏色區(qū)分不同類別。
- 直方圖和箱線圖:分析單個特征的分布和異常值。
- 混淆矩陣熱圖:直觀顯示分類結(jié)果的正確與錯誤情況。
- 決策邊界圖:通過繪制LDA的投影方向,可視化分類邊界。
在Jupyter中,這些圖表可以內(nèi)聯(lián)顯示,便于交互式分析和調(diào)試。通過可視化,我們不僅能驗證模型的有效性,還能深入理解數(shù)據(jù)的內(nèi)在結(jié)構(gòu)。
本實踐涵蓋了人工智能基礎(chǔ)軟件開發(fā)的核心環(huán)節(jié):從數(shù)據(jù)加載和預(yù)處理,到應(yīng)用Fisher線性分類算法,再到數(shù)據(jù)可視化分析。通過Jupyter Notebook的交互環(huán)境,開發(fā)者可以高效地實驗和學(xué)習(xí)。這種項目不僅鞏固了機器學(xué)習(xí)基礎(chǔ),還為更復(fù)雜的AI應(yīng)用打下了堅實基礎(chǔ)。建議讀者擴展此項目,例如嘗試其他分類算法或添加更多可視化技巧,以進(jìn)一步提升技能。